联童科技是一家智能化母婴童产业平台,从事母婴童行业以及互联网技术多年,拥有丰富的母婴门店运营和系统开发经验,在会员经营和商品经营方面,能够围绕会员需求,深入场景,更贴近合作伙伴和消费者,提供最优服务产品,公司致力于以技术来驱动母婴童产业的发展,公司也希望借助于大数据为客户提供更多智能数据分析和决策分析,大数据是公司重点发展的一部分,公司从成立初期起就搭建了大数据团队,有了大数据团队后,大数据调度平台的构建自然是最基础也是最重要的环节。
一、为什么选择incubator-dolphinscheduler
1、incubator-dolphinscheduler是一个由国内公司发起的开源项目,中国本土社区成员非常活跃,更加容易去进行社区沟通,同时联童也希望能加入到这个社区中,一起把这个由本土成员为主成立的社区做的更好。
2、incubator-dolphinscheduler 能够支撑非常多的应用场景
- 以DAG图的方式将Task按照任务的依赖关系关联起来,可实时可视化监控任务的运行状态
- 支持丰富的任务类型:Shell、MR、Spark、SQL(mysql、postgresql、hive、sparksql),Python,Sub_Process、Procedure,flink,datax,sqoop,http等
- 支持工作流定时调度、依赖调度、手动调度、手动暂停/停止/恢复,同时支持失败重试/告警、从指定节点恢复失败、Kill任务等操作
- 支持工作流优先级、任务优先级及任务的故障转移及任务超时告警/失败
- 支持工作流全局参数及节点自定义参数设置
- 支持资源文件的在线上传/下载,管理等,支持在线文件创建、编辑
- 支持任务日志在线查看及滚动、在线下载日志等
- 实现集群HA,通过Zookeeper实现Master集群和Worker集群去中心化
- 支持对
Master/Workercpu load,memory,cpu在线查看 - 支持工作流运行历史树形/甘特图展示、支持任务状态统计、流程状态统计
- 支持补数
- 支持多租户
- 支持国际化
其中DAG图 借鉴自spark ,在dolphinscheduler 一个工作流可以对应多个工作任务,每一个工作任务对应一个DAG中的节点。
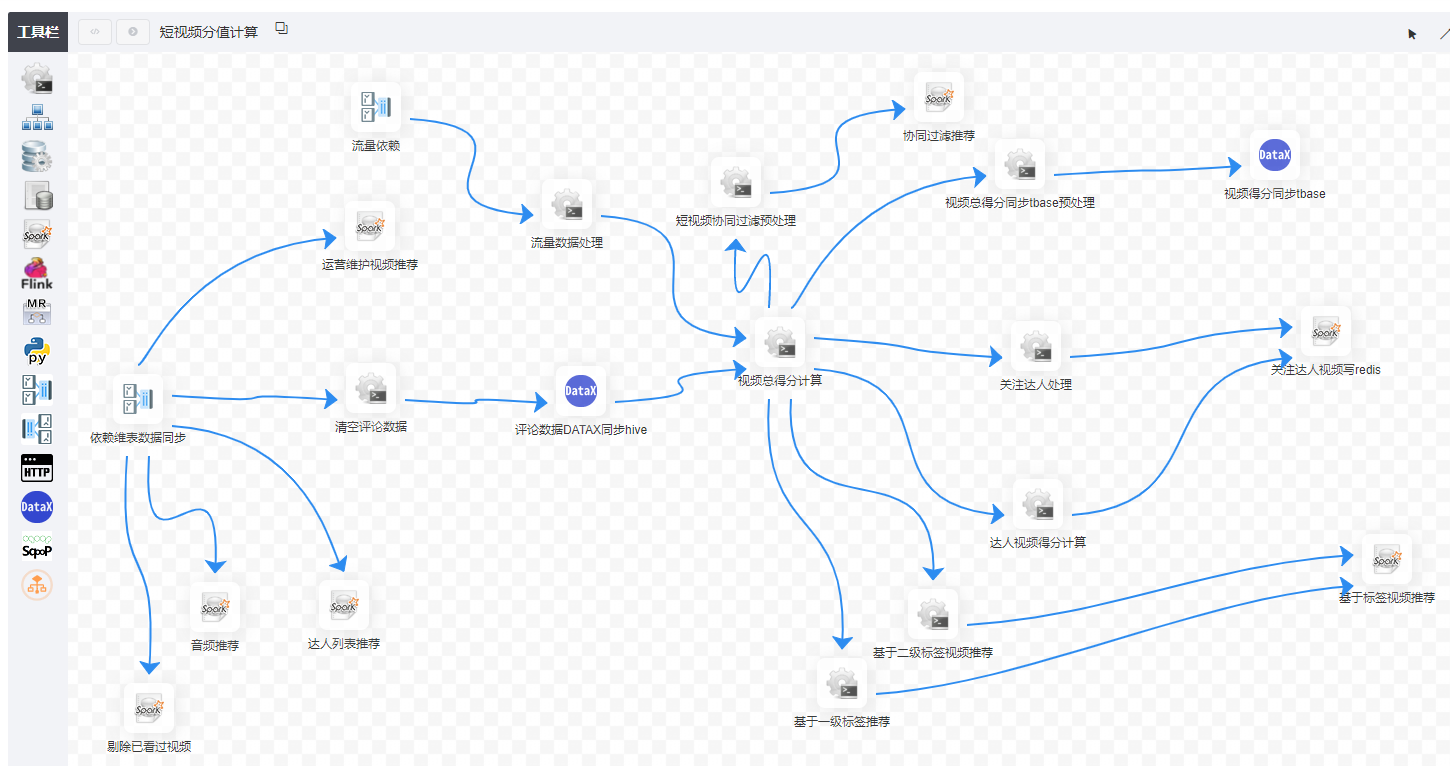
3、incubator-dolphinscheduler在保证了高并发和高可用的设计时,架构思路也相对简单,技术架构中没有引入非常多的复杂技术组件,降低了学习和维护的成本。
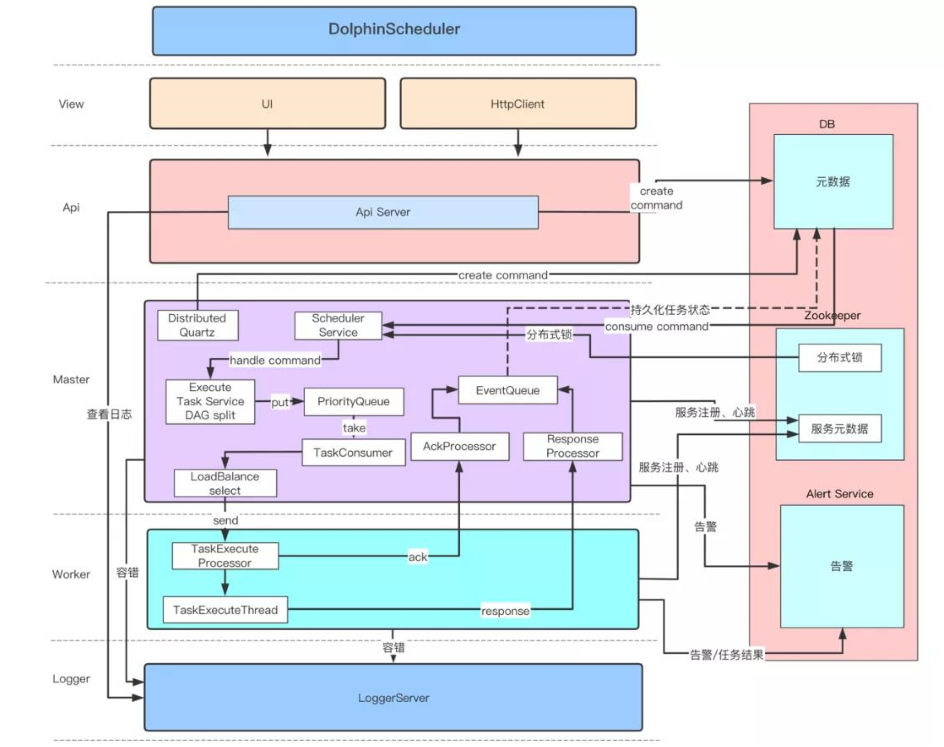
备注:此架构图摘自社区官方网站
incubator-dolphinscheduler在设计时,除了zookeeper外,没有引入太多复杂的技术组件。整个架构以zookeeper 作为集群管理,采用去中心化思想进行设计。
二、incubator-dolphinscheduler功能的不足
1、无法支持串行调度策略
incubator-dolphinscheduler 在一开始设计时,只支持并行调度,不支持串行调度,而在联童中,大部分场景都是需要串行运行的,也就是每一个工作流任务都只能有一个实例在运行,同一个工作流任务中必须要等前一个实例执行结束,下一个实例才能开始执行,这种场景大多出现在准实时任务中。
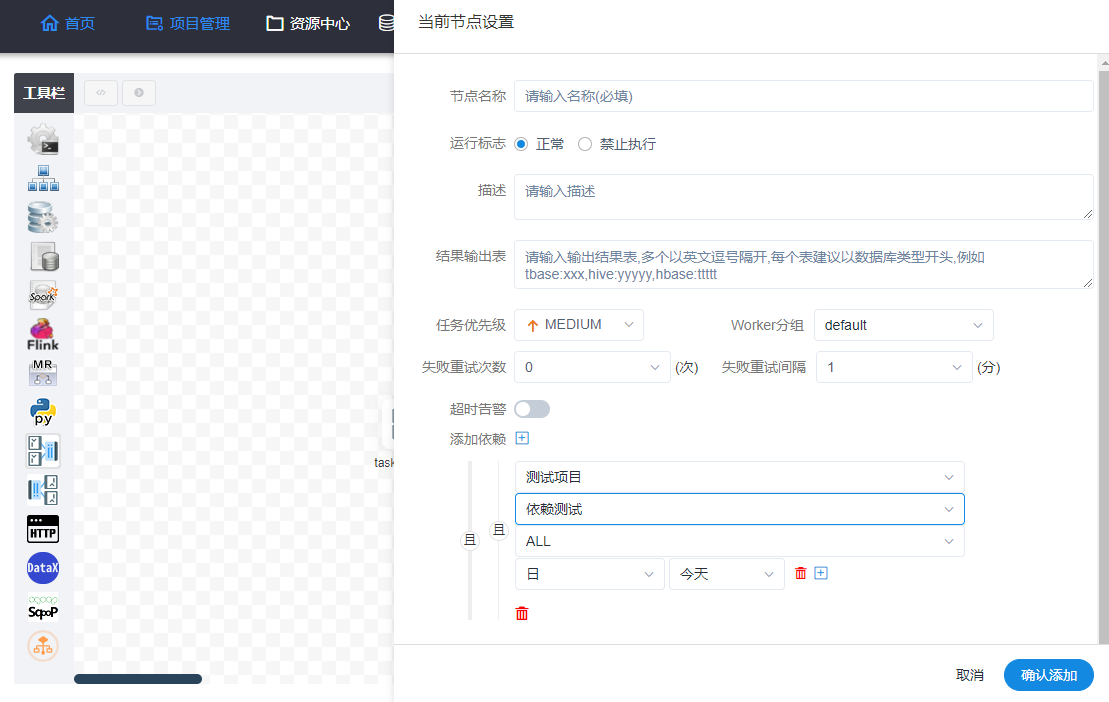
2、任务依赖不够强大,只能支持被动等待依赖执行成功,无法主动触发下游工作流实例运行
如下图所示,只能支持在创建任务时,被动去等待依赖执行成功,无法在当前任务执行成功后,主动去触发别的工作流任务执行。
3、部分模块中用户体验不足,并且在数据量大时,部分模块数据查询性能较慢
4、缺少比较完备的监控体系
在 incubator-dolphinscheduler 只提供了一些简单的监控,当有多大几千个任务在运行时,很难做到完备监控,更是缺少对每一个任务运行的性能分析。
三、我们对于incubator-dolphinscheduler的功能升级开发
1、增加串行调度的支持
如下图所示,我们在原有并行执行的基础上,增加了串行执行方式。
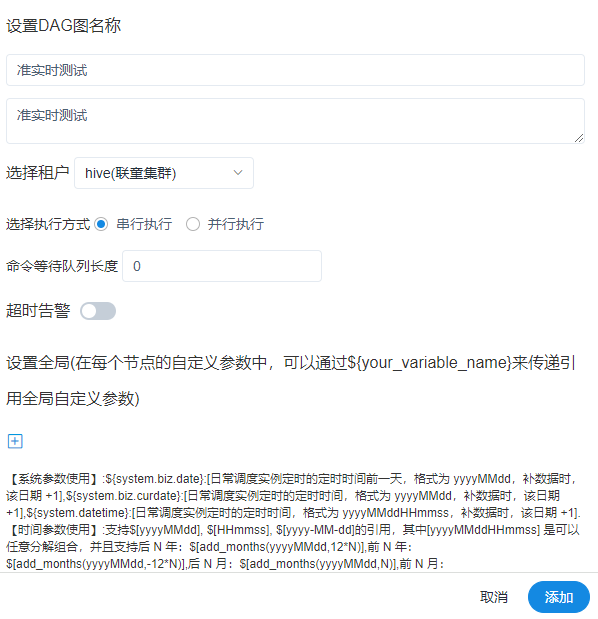
在串行执行时,我们还增加了串行执行的队列功能,每一任务都可以指定队列的长度大小。
2、增加主动触发下游工作流实例运行
如下图所示,我们在原有并行执行的基础上,增加主动触发下游一个或者多个工作流实例运行。

运行后效果如下:

3、一些较大的Bug修复
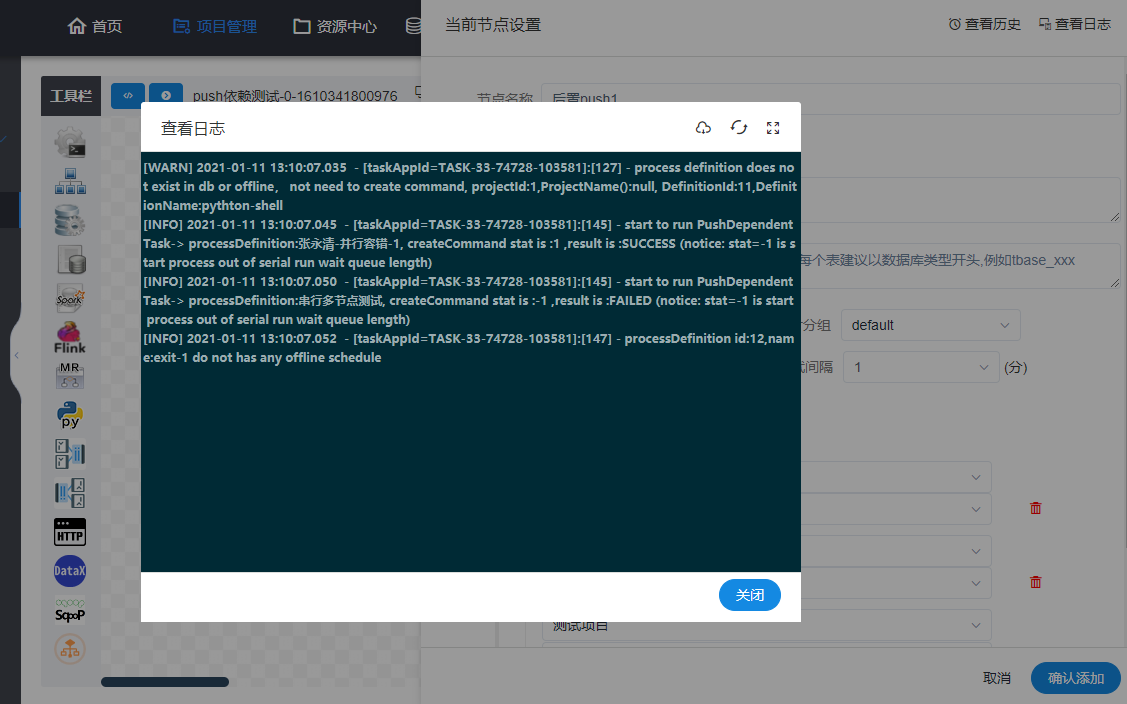
联童在使用 incubator-dolphinscheduler时,同样也踩过不少的坑,这里我们举其中一个例子,比如在内部使用时,同事反馈最多的问题就是调度任务的日志刷新不及时,有时候很久才能刷新出日志。后来经过源码分析,发现是源码中存在了一些不太健壮的处理导致了这个问题。
incubator-dolphinscheduler 中AbstractCommandExecutor.java 部分源码
/* * Licensed to the Apache Software Foundation (ASF) under one or more * contributor license agreements. See the NOTICE file distributed with * this work for additional information regarding copyright ownership. * The ASF licenses this file to You under the Apache License, Version 2.0 * (the "License"); you may not use this file except in compliance with * the License. You may obtain a copy of the License at * * * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */package org.apache.dolphinscheduler.server.worker.task;import static org.apache.dolphinscheduler.common.Constants.EXIT_CODE_FAILURE;import static org.apache.dolphinscheduler.common.Constants.EXIT_CODE_KILL;import static org.apache.dolphinscheduler.common.Constants.EXIT_CODE_SUCCESS;import org.apache.dolphinscheduler.common.Constants;import org.apache.dolphinscheduler.common.enums.ExecutionStatus;import org.apache.dolphinscheduler.common.thread.Stopper;import org.apache.dolphinscheduler.common.thread.ThreadUtils;import org.apache.dolphinscheduler.common.utils.HadoopUtils;import org.apache.dolphinscheduler.common.utils.LoggerUtils;import org.apache.dolphinscheduler.common.utils.OSUtils;import org.apache.dolphinscheduler.common.utils.StringUtils;import org.apache.dolphinscheduler.server.entity.TaskExecutionContext;import org.apache.dolphinscheduler.server.utils.ProcessUtils;import org.apache.dolphinscheduler.server.worker.cache.TaskExecutionContextCacheManager;import org.apache.dolphinscheduler.server.worker.cache.impl.TaskExecutionContextCacheManagerImpl;import org.apache.dolphinscheduler.service.bean.SpringApplicationContext;import java.io.BufferedReader;import java.io.File;import java.io.FileInputStream;import java.io.IOException;import java.io.InputStreamReader;import java.lang.reflect.Field;import java.nio.charset.StandardCharsets;import java.util.ArrayList;import java.util.Collections;import java.util.LinkedList;import java.util.List;import java.util.concurrent.ExecutorService;import java.util.concurrent.TimeUnit;import java.util.function.Consumer;import java.util.regex.Matcher;import java.util.regex.Pattern;import org.slf4j.Logger;/** * abstract command executor */public abstract class AbstractCommandExecutor { /** * rules for extracting application ID */ protected static final Pattern APPLICATION_REGEX = Pattern.compile(Constants.APPLICATION_REGEX); protected StringBuilder varPool = new StringBuilder(); /** * process */ private Process process; /** * log handler */ protected Consumer<List<String>> logHandler; /** * logger */ protected Logger logger; /** * log list */ protected final List<String> logBuffer; /** * taskExecutionContext */ protected TaskExecutionContext taskExecutionContext; /** * taskExecutionContextCacheManager */ private TaskExecutionContextCacheManager taskExecutionContextCacheManager; public AbstractCommandExecutor(Consumer<List<String>> logHandler, TaskExecutionContext taskExecutionContext, Logger logger) { this.logHandler = logHandler; this.taskExecutionContext = taskExecutionContext; this.logger = logger; this.logBuffer = Collections.synchronizedList(new ArrayList<>()); this.taskExecutionContextCacheManager = SpringApplicationContext.getBean(TaskExecutionContextCacheManagerImpl.class); } /** * build process * * @param commandFile command file * @throws IOException IO Exception */ private void buildProcess(String commandFile) throws IOException { // setting up user to run commands List<String> command = new LinkedList<>(); //init process builder ProcessBuilder processBuilder = new ProcessBuilder(); // setting up a working directory processBuilder.directory(new File(taskExecutionContext.getExecutePath())); // merge error information to standard output stream processBuilder.redirectErrorStream(true); // setting up user to run commands command.add("sudo"); command.add("-u"); command.add(taskExecutionContext.getTenantCode()); command.add(commandInterpreter()); command.addAll(commandOptions()); command.add(commandFile); // setting commands processBuilder.command(command); process = processBuilder.start(); // print command printCommand(command); } .......... /** * get the standard output of the process * * @param process process */ private void parseProcessOutput(Process process) { String threadLoggerInfoName = String.format(LoggerUtils.TASK_LOGGER_THREAD_NAME + "-%s", taskExecutionContext.getTaskAppId()); ExecutorService parseProcessOutputExecutorService = ThreadUtils.newDaemonSingleThreadExecutor(threadLoggerInfoName); parseProcessOutputExecutorService.submit(new Runnable() { @Override public void run() { BufferedReader inReader = null; try { inReader = new BufferedReader(new InputStreamReader(process.getInputStream())); String line; long lastFlushTime = System.currentTimeMillis(); while ((line = inReader.readLine()) != null) { if (line.startsWith("${setValue(")) { varPool.append(line.substring("${setValue(".length(), line.length() - 2)); varPool.append("$VarPool$"); } else { logBuffer.add(line); lastFlushTime = flush(lastFlushTime); } } } catch (Exception e) { logger.error(e.getMessage(), e); } finally { clear(); close(inReader); } } }); parseProcessOutputExecutorService.shutdown(); }................ /** * when log buffer siz or flush time reach condition , then flush * * @param lastFlushTime last flush time * @return last flush time */ private long flush(long lastFlushTime) { long now = System.currentTimeMillis(); /** * when log buffer siz or flush time reach condition , then flush */ if (logBuffer.size() >= Constants.DEFAULT_LOG_ROWS_NUM || now - lastFlushTime > Constants.DEFAULT_LOG_FLUSH_INTERVAL) { lastFlushTime = now; /** log handle */ logHandler.accept(logBuffer); logBuffer.clear(); } return lastFlushTime; } /** * close buffer reader * * @param inReader in reader */ private void close(BufferedReader inReader) { if (inReader != null) { try { inReader.close(); } catch (IOException e) { logger.error(e.getMessage(), e); } } } protected List<String> commandOptions() { return Collections.emptyList(); } protected abstract String buildCommandFilePath(); protected abstract String commandInterpreter(); protected abstract void createCommandFileIfNotExists(String execCommand, String commandFile) throws IOException;}在这段源码中,parseProcessOutput(Process process) 方法是负责任务日志的获取以及Flush。 但是由于采用了BufferedReader 中的readLine() 方法来读取任务进程的process.getInputStream()日志,由于readLine() 是一个阻塞方法,
flush(long lastFlushTime) 方法在处理时有一个判断条件if (logBuffer.size() >= Constants.DEFAULT_LOG_ROWS_NUM || now - lastFlushTime > Constants.DEFAULT_LOG_FLUSH_INTERVAL),只有当日志条数达到64条或者间隔1s时才会
flush。按理说,代码其实是要实现至少每隔1s会flash 一次日志,但是由于readLine() 是一个阻塞方法,所以并不会一直在执行,而是readLine()必须是读取到新数据后,才会执行flush方法。 那么在出现1s内产生的任务日志不满足64条,而任务又很久没有新日志出现时,就会触发这个bug。例如执行如下一个shell 脚本任务,由于每个执行步骤产生的日志少,而且每个步骤执行的时间又很久,时间间隔很大,就会出现很久都不会刷新上一次产生的日志。
#!/bin/bashecho "hello world"exec 10msleep 100000secho "hello world2"exec 10msleep 100000secho "hello world3"exec 10msleep 100000s
之后我们对这段源码进行了重写,采用了两个线程进行处理,一个线程负责readline(),一个线程负责flush.做到在readline()方法的线程阻塞时,不影响flush线程的处理。
/* * Licensed to the Apache Software Foundation (ASF) under one or more * contributor license agreements. See the NOTICE file distributed with * this work for additional information regarding copyright ownership. * The ASF licenses this file to You under the Apache License, Version 2.0 * (the "License"); you may not use this file except in compliance with * the License. You may obtain a copy of the License at * * * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */
public abstract class AbstractCommandExecutor { /** * rules for extracting application ID */ protected static final Pattern APPLICATION_REGEX = Pattern.compile(Constants.APPLICATION_REGEX); /** * process */ private Process process; /** * log handler */ protected Consumer<List<String>> logHandler; /** * logger */ protected Logger logger; /** * log list */ protected final List<String> logBuffer; protected boolean logOutputIsScuccess = false; /** * taskExecutionContext */ protected TaskExecutionContext taskExecutionContext; /** * taskExecutionContextCacheManager */ private TaskExecutionContextCacheManager taskExecutionContextCacheManager;......... /** * get the standard output of the process * * @param process process */ private void parseProcessOutput(Process process) { String threadLoggerInfoName = String.format(LoggerUtils.TASK_LOGGER_THREAD_NAME + "-%s", taskExecutionContext.getTaskAppId()); ExecutorService getOutputLogService = ThreadUtils.newDaemonSingleThreadExecutor(threadLoggerInfoName + "-" + "getOutputLogService"); getOutputLogService.submit(() -> { BufferedReader inReader = null; try { inReader = new BufferedReader(new InputStreamReader(process.getInputStream())); String line;while ((line = inReader.readLine()) != null) { logBuffer.add(line); } } catch (Exception e) { logger.error(e.getMessage(), e); } finally { logOutputIsScuccess = true; close(inReader); } }); getOutputLogService.shutdown(); ExecutorService parseProcessOutputExecutorService = ThreadUtils.newDaemonSingleThreadExecutor(threadLoggerInfoName); parseProcessOutputExecutorService.submit(() -> { try { long lastFlushTime = System.currentTimeMillis(); while (logBuffer.size() > 0 || !logOutputIsScuccess) { if (logBuffer.size() > 0) { lastFlushTime = flush(lastFlushTime); } else { Thread.sleep(Constants.DEFAULT_LOG_FLUSH_INTERVAL); } } } catch (Exception e) { logger.error(e.getMessage(), e); } finally { clear(); } }); parseProcessOutputExecutorService.shutdown(); }....... /** * when log buffer siz or flush time reach condition , then flush * * @param lastFlushTime last flush time * @return last flush time */ private long flush(long lastFlushTime) throws InterruptedException { long now = System.currentTimeMillis(); /** * when log buffer siz or flush time reach condition , then flush */ if (logBuffer.size() >= Constants.DEFAULT_LOG_ROWS_NUM || now - lastFlushTime > Constants.DEFAULT_LOG_FLUSH_INTERVAL) { lastFlushTime = now; /** log handle */ logHandler.accept(logBuffer); logBuffer.clear(); } return lastFlushTime; }.......}
4、将调度系统的监控接入到prometheus和grafana中
incubator-dolphinscheduler 只提供了一些如下的简单实时监控,尤其缺少对任务的监控。

联童在此基础上,引入了prometheus和grafana。

使用prometheus和grafana 不但可以监控到调度系统任务的总体运行,也可以监控到单个任务的运行耗时曲线等。
5、对incubator-dolphinscheduler 的性能优化
待稍后晚点补充
四、联童对于开源社区的拥抱和回馈
联童虽然是一家新兴起的母婴童公司,但是在成立的初始,就秉承着以技术来驱动母婴童产业的发展,公司拥有一个非常好的技术团队,也一直在拥抱开源社区,目前已经引入了incubator-dolphinscheduler、prometheus、grafana 、hadoop、spark、flink、hive、presto......等很多开源项目来支撑公司的技术驱动。在未来,联童也一定回不断的去回馈开源社区,去提供更多的Pull requests,贡献自己的一份力量。
【备注】本篇文章 摘选自【联童直通车】公众号: https://mp.weixin.qq.com/s?__biz=MzI5NDM3MzU0MQ==&mid=2247483996&idx=1&sn=cdb180446fa215705b21e09bdfb632fd&chksm=ec629396db151a80ee6c8b7f860cf4061b72e2bf0f1f099ef281bc914d8f5bcd60e70c54c2da&scene=126&&sessionid=1614058343&version=3.1.1.3006&platform=win#rd
欢迎加入APachec dolphinscheduler社区
https://github.com/apache/incubator-dolphinscheduler (请记得fork和star)
订阅邮件列表
用自己的邮箱向dev-subscribe@dolphinscheduler.apache.org发送一封邮件,主题和内容任意。
接收确认邮件并回复。完成步骤1后,将收到一封来自dev-help@dolphinscheduler.apache.org的确认邮件(如未收到,请确认邮件是否被自动归入垃圾邮件、推广邮件、订阅邮件等文件夹)。然后直接回复该邮件,或点击邮件里的链接快捷回复即可,主题和内容任意。
接收欢迎邮件。完成以上步骤后,会收到一封主题为WELCOME to dev@dolphinscheduler.apache.org的欢迎邮件,至此已成功订阅Apache DolphinScheduler(Incubating)的邮件列表。
原文转载:http://www.shaoqun.com/a/579625.html
东西网:https://www.ikjzd.com/w/1238
ask me:https://www.ikjzd.com/w/2459
联童科技是一家智能化母婴童产业平台,从事母婴童行业以及互联网技术多年,拥有丰富的母婴门店运营和系统开发经验,在会员经营和商品经营方面,能够围绕会员需求,深入场景,更贴近合作伙伴和消费者,提供最优服务产品,公司致力于以技术来驱动母婴童产业的发展,公司也希望借助于大数据为客户提供更多智能数据分析和决策分析,大数据是公司重点发展的一部分,公司从成立初期起就搭建了大数据团队,有了大数据团队后,大数据调度平
洋老板:https://www.ikjzd.com/w/2779
法瑞儿:https://www.ikjzd.com/w/412
vava:https://www.ikjzd.com/w/2780
亚马逊印度站开店:https://www.ikjzd.com/w/2559
ebay的Marketing-Promotion-Sales event + Markdown工具:https://www.ikjzd.com/home/109888
一名成熟的亚马逊卖家,应学会产品的分类管理:https://www.ikjzd.com/home/128105
No comments:
Post a Comment